1강 Introduction to Reinforcement Learning
강화학습의 이론을 기본부터 공부 하기 위해서 UCL Courese On RL 강의를 보면서 정리
전반적인 용어 정리와 강화학습에 대해 소개한다.
About RL
- RL은 누군가가 정답을 알려주지 않음
- 오로지 reward 라고 하는 보상 시스템에 따라서 학습
- 어떠한 선택을 한 결과가 좋은 결과인지 여부는 이후 다음, 다음, 다음의 먼 미래에 알 수 있음 (delay가 존재)
- Agent의 선택에 따라 어떠한 정보들이 결과로 받아들일지 결정
Rewards
- Scalar 신호
- Agent의 행동이 좋은 결과인지 나쁜 결과인지 평가
- Time Step에 어떤 행동을 했는지에 따라 달라짐
- 최상의 보상을 받는 것이 목표
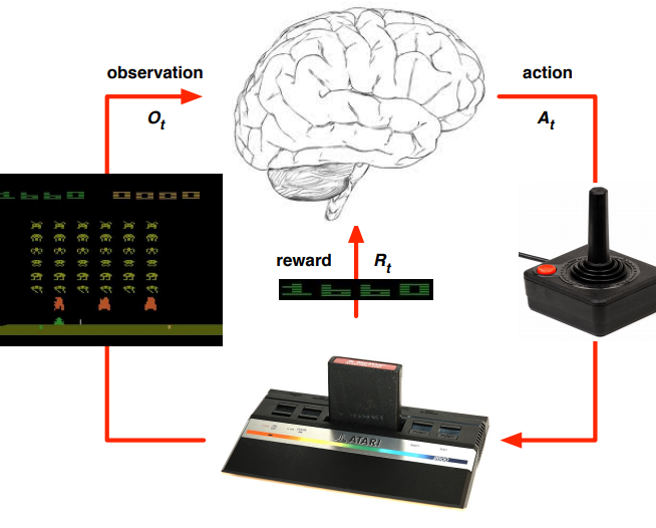
Agent and Environment
- Agent와 Environment 간의 상호작용으로 Agent는 어떤 행동을 할 지를 선택
- Agent가 Environment에서 어떤 행동을 하고 주변 정보를 관찰하고 그에 대한 보상을 받는 사이클이 계속 돌아감
- State는 history의 함수
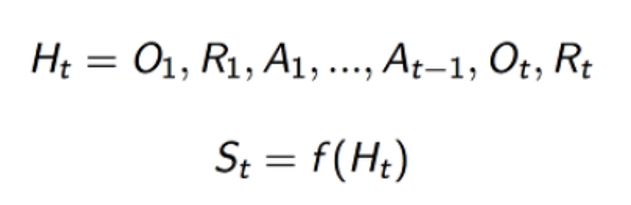
State
State는 Environment State와 Agent State로 나눌 수 있음
Environment State
- Ste 라고 표현
- Environment가 가지고 있는 다양한 정보
- Agent는 모든 환경에 대한 정보를 볼 수 없음
Agent State
- Sta 라고 표현
- Agent가 가지고 있는 다양한 정보
- 주식 Agent라면 거래시 참고되는 지표가 될 수 있다.(ex 재무재표, 주가등)
Information State(Markov state)
-
현재 상태의 조건에서 다음 상태가 발생할 확률과 과거의 모든 상태의 조건에서 다음 상태가 발생할 확률이 같을 때, 이 때의 St는 Markov property라고 한다.
-
현재 주어진 상태는 과거의 모든 history 정보를 포함하고 있기 때문에 현재의 정보가 중요하며, 과거의 정보들은 의미가 없어진다.

RL의 문제점
Rat Example
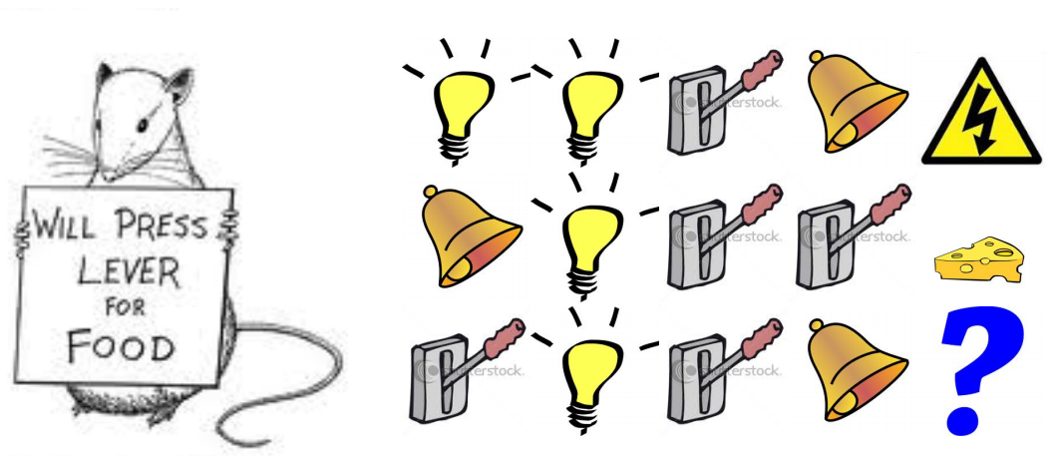
•마지막 3개를 state로 했을때 감전을 선택
•전등, 벨, 레버의 개수하면 치즈을 선택
•4개의 정보를 다하면 ????
Environments에 따른 분류
Fully observability
- Agent가 모든 정보를 알 수 있는 경우를 Fully observability라고 함.
- Ot=Sta=Ste
- 이러한 것을 Markov decision process(MDP)라고 함.
Partial Observability
- 일반적으로 우리는 간접적으로 환경을 접하고 있기 때문에 Partial Observability에 있다.
- agent state ≠ environment state 정보가 동일하지 않다.(POMDP)
- agent는 현재 시점의 state를 만들어야 한다
- history 전체를 사용하는 방법
- 과거 상태가 발생한 확률, 즉 통계적인 방식
- RNN 과 같은 방식
Components of an RL Agent
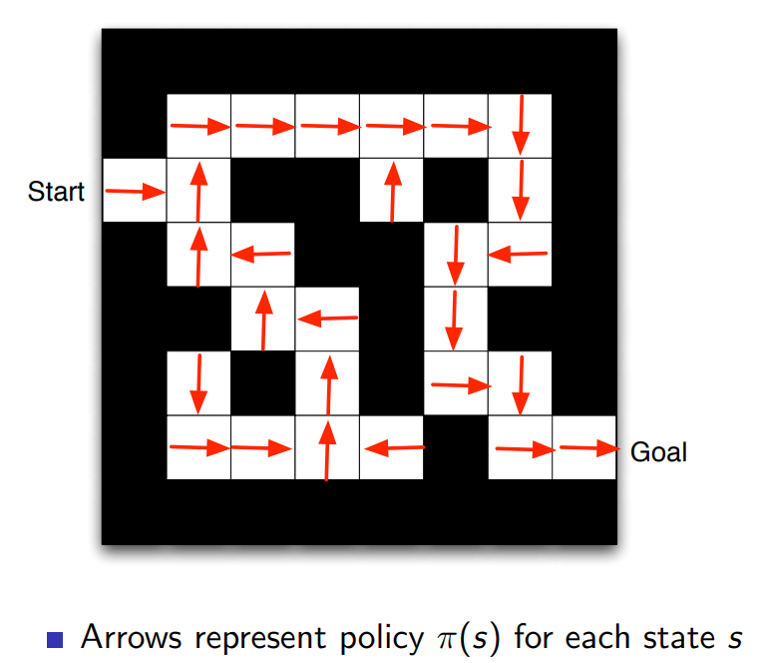
Policy
- 어떤 상태에서 이 agent가 어떤 행동을 해야하는가?
- Deterministic policy : 죄를 지으면 감옥에 가야한다.
- Stochastic policy : 교통신호를 위반하는 죄를 지었지만 경찰에게 발견된 확률
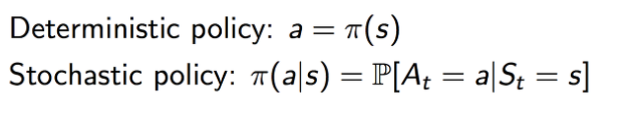
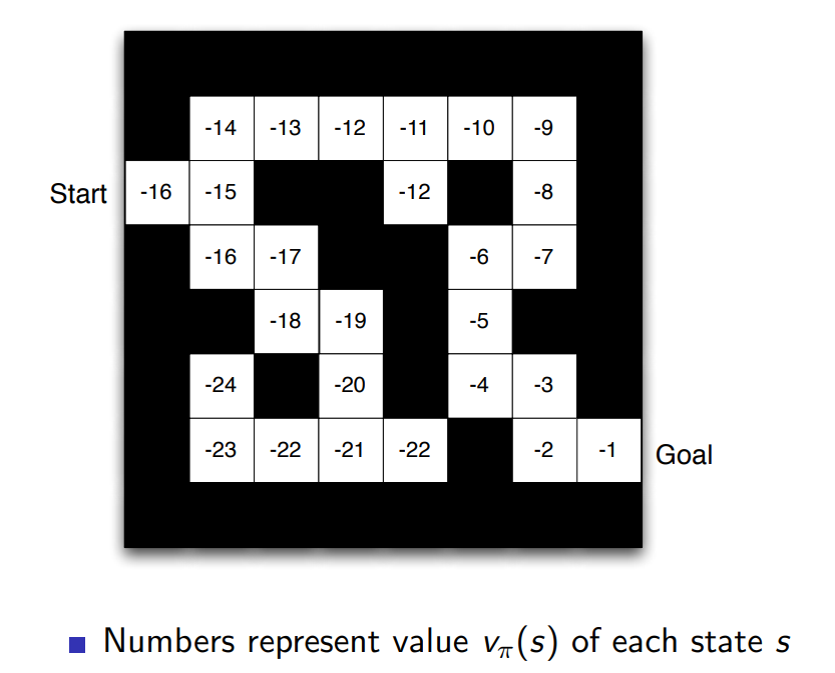
Value function
-
reward를 예측하기 위한 것
-
이 가치가 높으면 좋은 상태가 되고 좋은 상태가 아니라면 낮아지게 됨
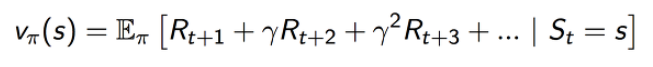
Model
- 현재 상태에서 어떤 행동을 했을 때 환경이 줄 것이라고 예상되는 정보 (다음 상태 정보와 보상을 표현)
- P predicts the next state
- R predicts the next (immediate) reward
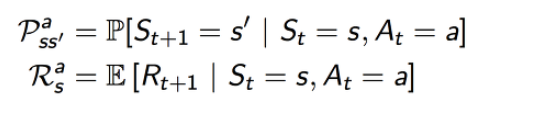
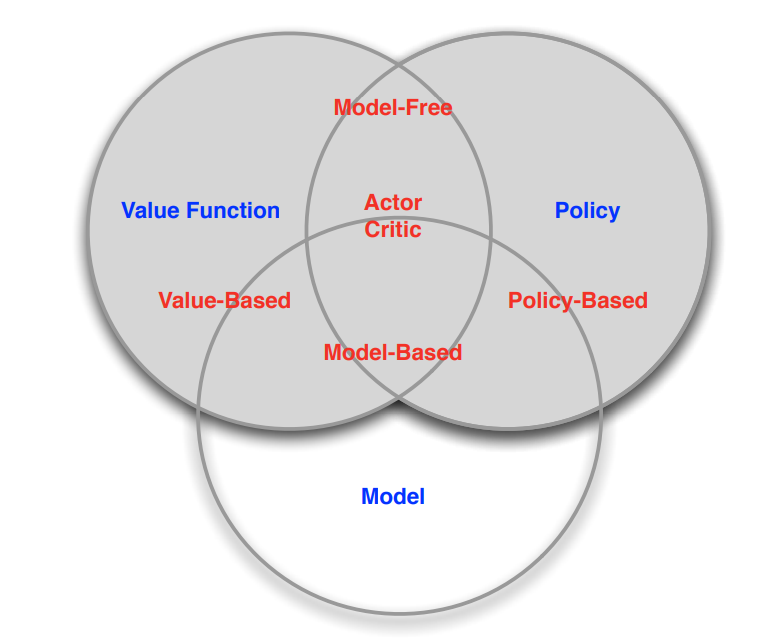
Categorizing RL agents
- Value Based
No Policy- Value Function
- Policy Based
- Policy
No Value Function
- Actor Critic
- Policy
- Value Function
- Model Free
- Policy and/or Value Function
No Model
- Model Based
- Policy and/or Value Function
- Model
Leave a comment