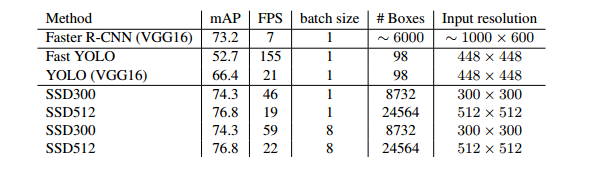
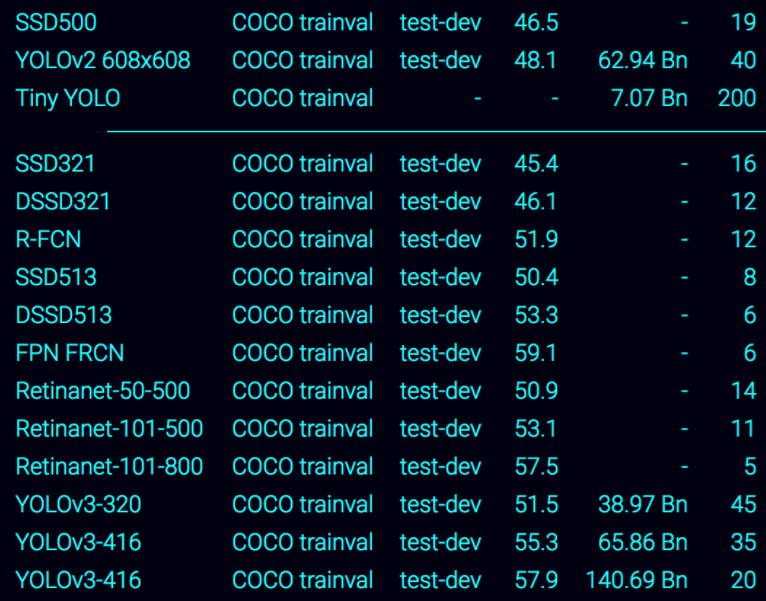
SSD(Single Shot MultiBox Detector) 논문 리뷰
Single Shot MultiBox Detector논문을 리뷰
SSD : Single Shot MultiBox Detector
사진의 변형 없이 한장으로 훈련, 검출을 하는 Detector

특징
- Bbox proposal을 뽑아내는 부분과 그 후처리를 생략
- 여러가지 크기의 feature map에 Conv layer 처리를 하고 합치는 방식
- YOLO는 최종 특징맵에만 경계 박스와 클래스 정보가 있는데 비해 SSD는 여러 레이어에 정보가 분산
- Class 수는 pascal voc기준 background 포함 21개
- k X (Classes + 4) 형태인데 k는 default box개수(aspect ratio)를 의미
- +4는 (x, y, w, h) bbox 데이터 의미
구조
m x n 을 p 채널을 가지고 있는 feature map은, 각 위치 마다 3 x 3 x p kernel들 을 적용할 수 있으며, 각 kernel(filter) 은 카테고리 점수나 bounding box offset 점수를 알려주게 된다.
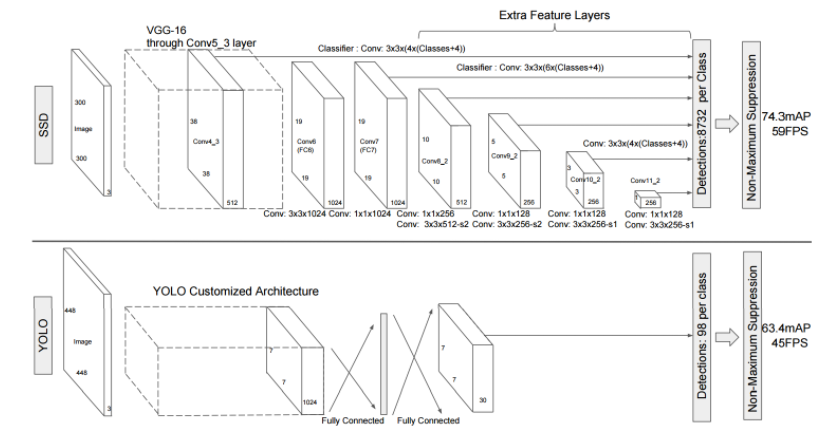
conv4_3 - 38x38x(4x(Classes+4)) = 5776x(Classes+4)
conv7 - 19x19x(6x(Classes+4)) = 2166x(Classes+4)
conv8_2 - 10x10x(6x(Classes+4)) = 600x(Classes+4)
conv9_2 - 5x5x(6x(Classes+4)) = 150x(Classes+4)
conv10_2 - 3x3x(4x(Classes+4)) = 36x(Classes+4)
conv11_2 - 1x1x(4x(Classes+4)) = 4x(Classes+4)
모두 더하면 8,732x(Classes+4)로 클래스당 8,732개의 경계박스를 예측
Approach
- 한가지 feature map에서 구하려면 bounding box의 크기 차이가 크기때문에 box의 크기 추정부터 위치 주정까지 많은 과정이 필요하지만
- feature map을 여러 개의 크기로 만들어서, 큰 map에서는 작은 물체의 검출을 작은 map에서는 큰 물체의 검출을함
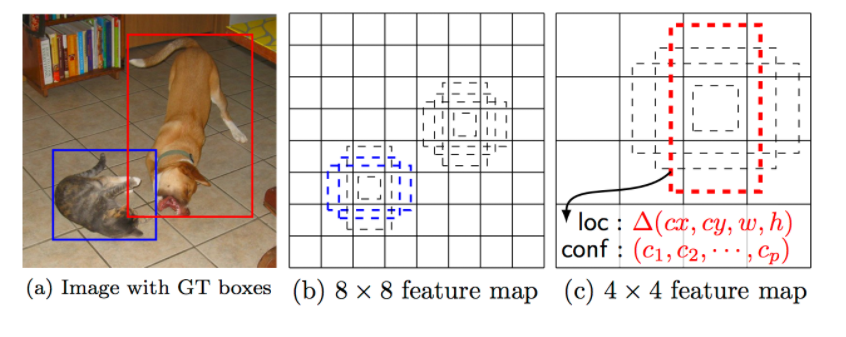
- Default Box - 여러가지 미리 정의된 박스
- 6개를 이용한다면 1:1, 1:1, 1:2, 2:1, 1:3, 3:1 식으로 사용
- 실제 박스와 예측 박스가 정확히 일치하는 것이 제일 좋겠지만, 너무나도 어렵고 비효율적이다. 그래서 aspect ratio라는 개념을 도입하였다. 이는 상자가 가질만한 비율을 몇 가지만 추려서 정답은 이 안에 있어! 라고 추정하는 것이다. (이 비율들을 가진 상자들을 default boxes라 부른다.)
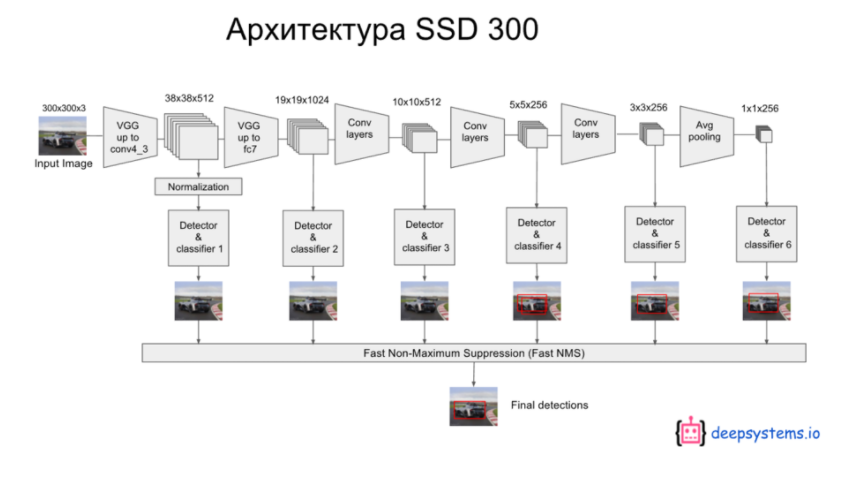
Fast NMS(Fast Non-Maximum Suppression)
- 첫번째 네트워크 그림의 화살표에서는 생략되었던 Detector&classifier x 를 통해서 경계박스와 클래스 정보를 얻을 것을 보여준다.
- 6개의 classifier 의 예측 중에서 신뢰도가 가장 큰 것 하나만 남기고 나머지는 모두 지우는 NMS 알고리즘을 사용한다.
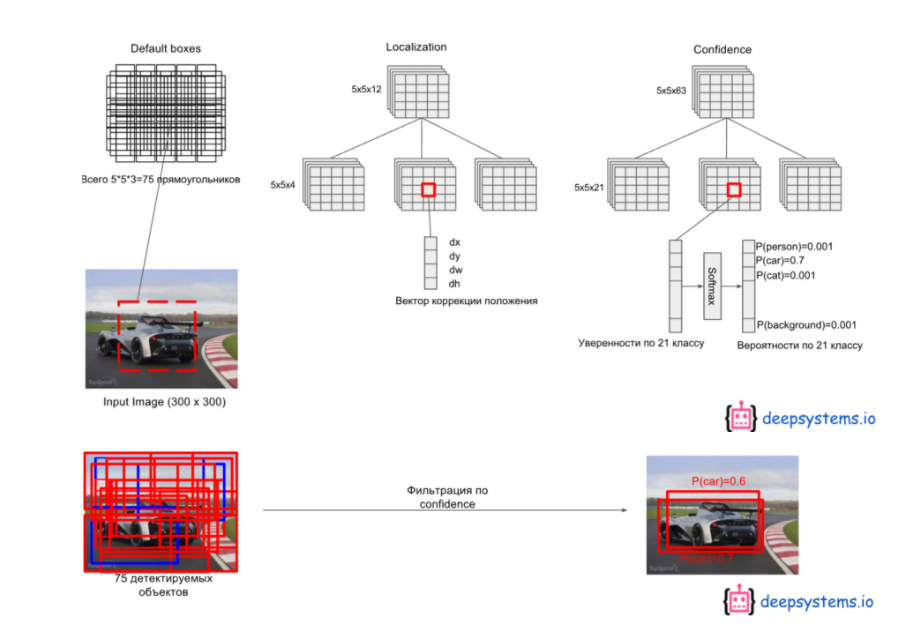
- 5x5x(3x(21+4)) = 75x(21+4)
- (21+4) 에는 4개의 경계박스 좌표(중심 x,중심 y, 가로길이,세로길이) 정보와 그것이 21개 클래스 중에서 어디에 속하는 지에 대한 정보가 들어있다
- 신뢰도 높은 것만 남기면 대부분의 경계박스는 사라진다.
Training
-
Matching Strategy
-
SSD가 예측한 박스와 실제 박스가 일치하는 지를 확인하는것
-
jaccard overlap, intersection over Union을 사용
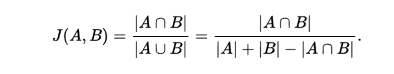
-
SSD에서는 이값이 일정값(논문에서 threshold > 0.5)를 넘기기만 하면 일치한다고 가정
-
threshold를 넘는 상자를 모두 선택하는 이유는 높은 정확도를 가진 상자를 한꺼번에 여러번 학습시킴으로써 하나만 고르는 것보다 높은 학습율을 얻기 위함
-
-
Training objective
-
다른 네트워크와 마찬가지로 loss를 줄이는 방향으로 학습
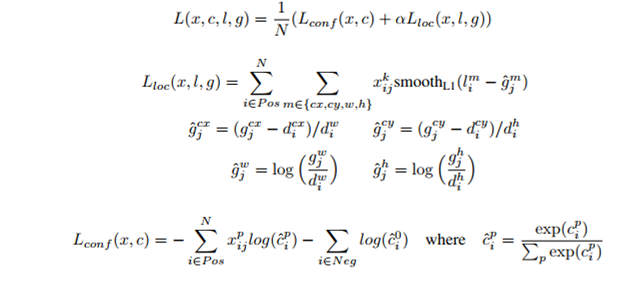
N: 검출된 박스의 개수 ( N=0 일 시에 loss를 0으로 설정함)
g: ground truth box, 실제 박스의 변수들을 의미한다.
d: default box, default box
c: category, 말 그대로 카테고리
l: predicted boxes, 예상된 박스의 변수들을 의미한다.
cx, cy: offset of center
w,h : width and height
alpha: weight term, 이 값은 교차 검증에 의해 1로 정해졌다고 한다.
-
-
scale & Aspect rations for default boxes
-
feature map에서 default box의 크기가 얼마나 되는지를 구함
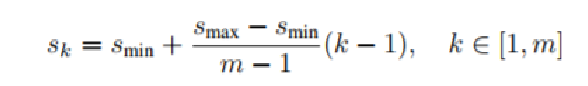
-
aspect ratio를 구함
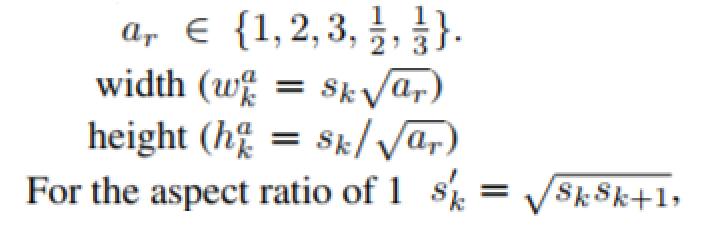
-
-
Hard negative mining
- matching을 돌리면 positive에 비해 너무많은 negative sample이나옴
- 따라서 모든 mathcing 상자들 중, 점수가 상대적으로 높은 것들을 negative로 학습시킨다.
-
Data augmentation
- 입력이미지를 날것으로 넣으면 물체나 환경 변화에 대처를 잘못하게 되므로 입력이미지를 다음 세 개 중에 랜덤으로 선택해서 집어넣어 좀더 robust하게 훈련시킨다
- 입력 이미지를 그대로 넣기
- 최소 Jaccard overlap이 0.1, 0.3, 0.5, 0.7, 0.9 인 샘플 패치를 넣기
- 랜덤으로 정해진 패치를 넣기
- sample들이 size는 원본 사이즈, 혹은 그의 0.1 중에 선택되며 aspect ratio는 1/2과 2사이로 결정된다
- 입력이미지를 날것으로 넣으면 물체나 환경 변화에 대처를 잘못하게 되므로 입력이미지를 다음 세 개 중에 랜덤으로 선택해서 집어넣어 좀더 robust하게 훈련시킨다
Leave a comment