3강 Planning by dynamic programming
3장에서는 2장에서 배운 MDP에서 Control 즉 Optimal policy을 찾는 방법에 대해 스터디 한다.
이해를 돕기위해 https://sumniya.tistory.com/10?category=781573에서 예제를 참고함.
Dynamic Programming
- 복잡한 문제를 간단한 여러 개의 문제로 나누어 푸는 방법
- 서브 문제를 해결하면 원래의 문제도 해결할 수 있다.
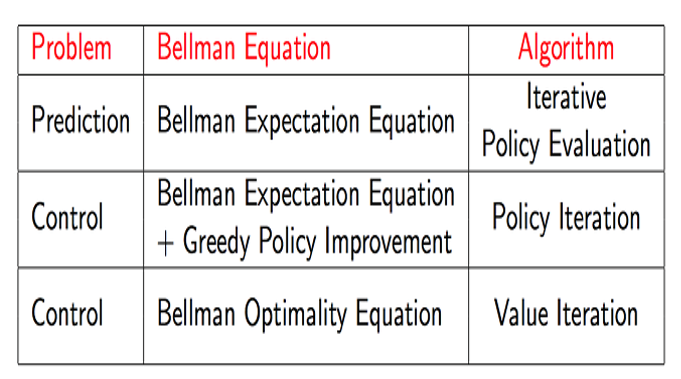
Prediction & control
- Prediction: evaluate the future -> value function
- control : optimize the future -> optimal policy
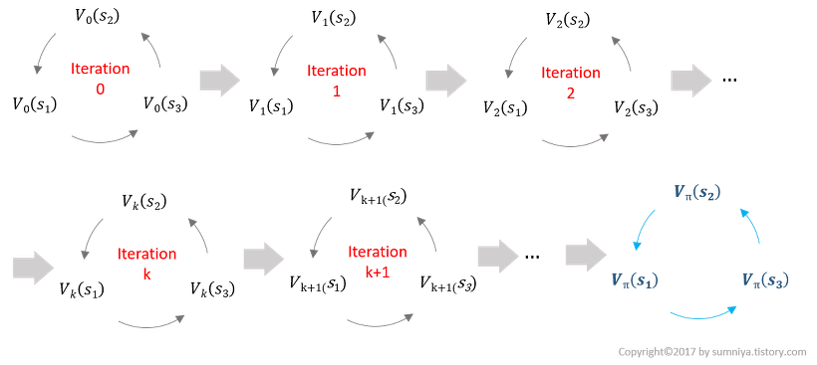
Iterative Policy Evaluation
- Bellman Expectation을 사용해서 반복적으로 연산을 하면 value 값이 수렴
- 수렴된 value들을 사용하여 policy를 만들 수 있음
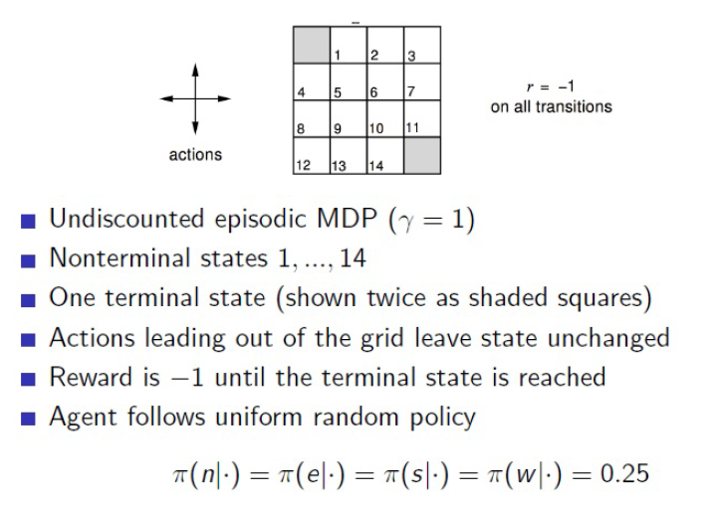
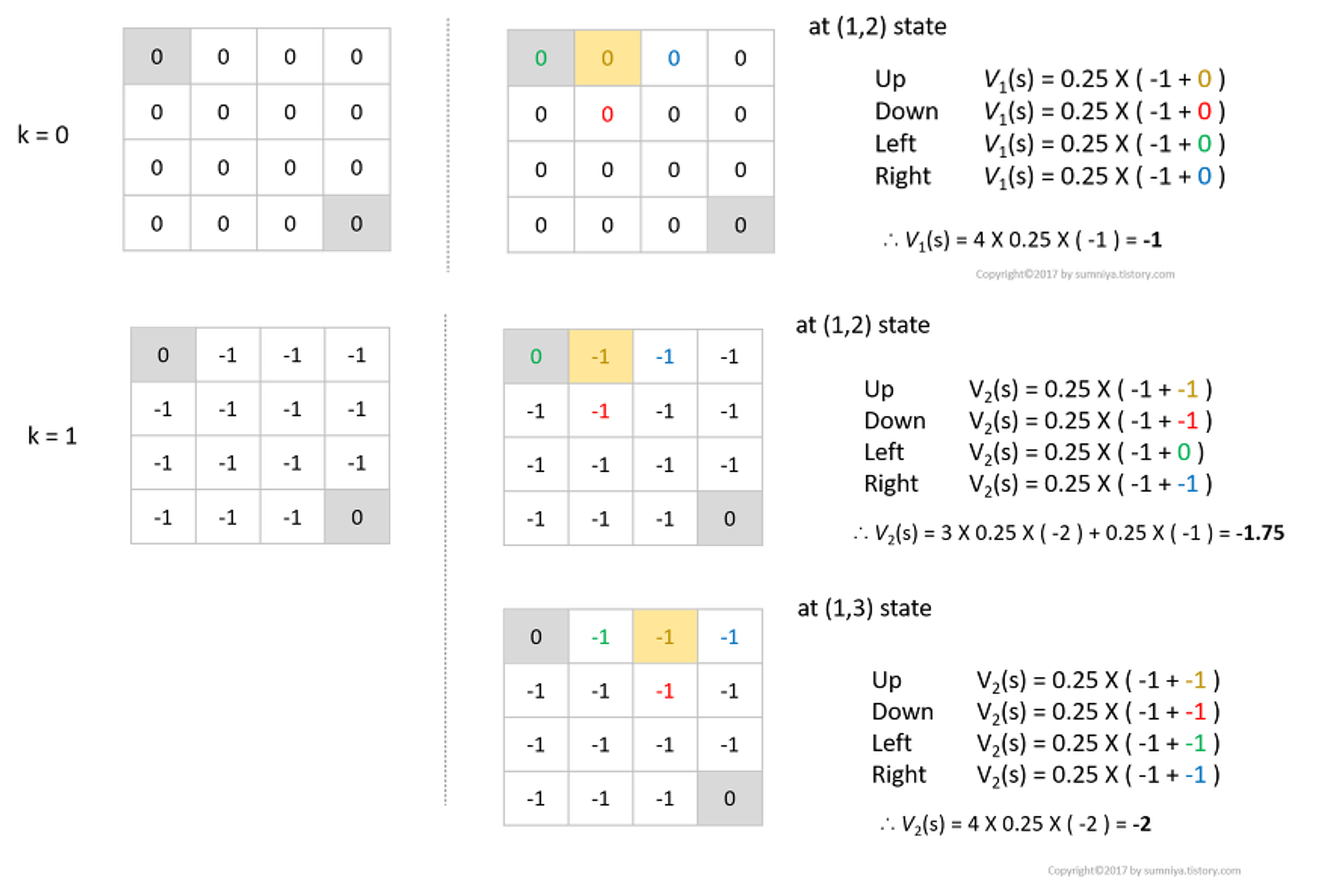
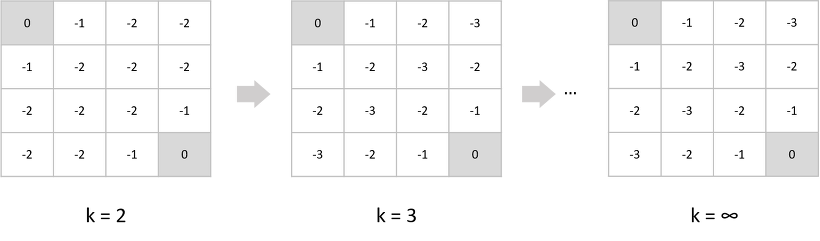
Example(grid-world)
- 1~14개의 state를 가지고 있고 한번 transition을 할 때마다 보상이 -1이 주어짐
- 회색으로 되어있는 두개의 terminal state가 존재
- action은 random policy를 따름
Bellman Expectation Equation for Vπ
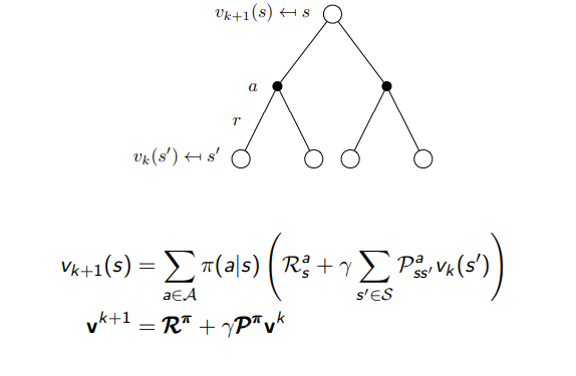
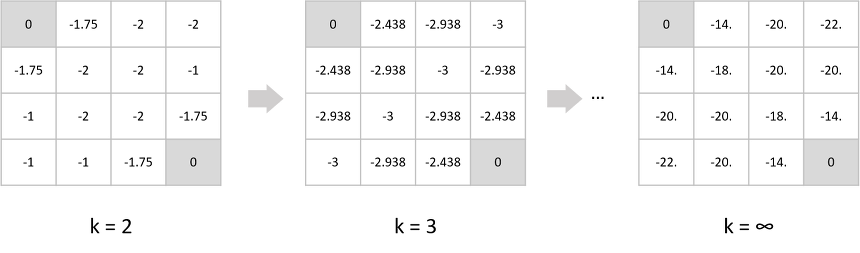
Example: Iterative Policy Evaluation
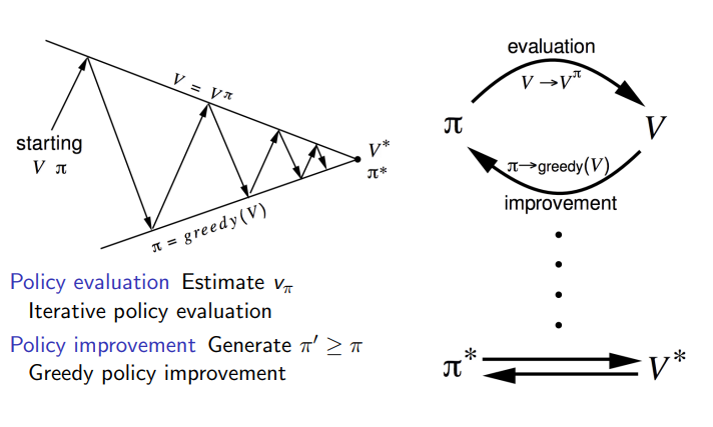
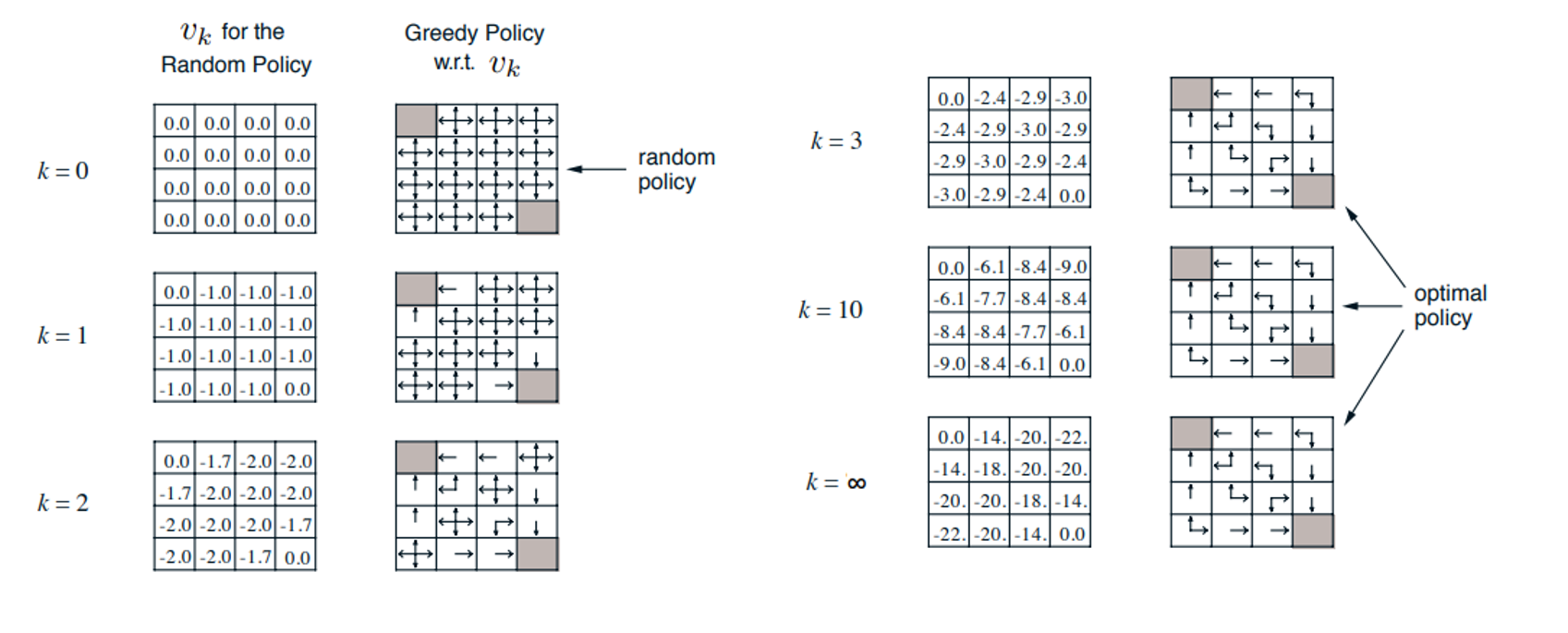
Policy iteration
Example: Policy iteration
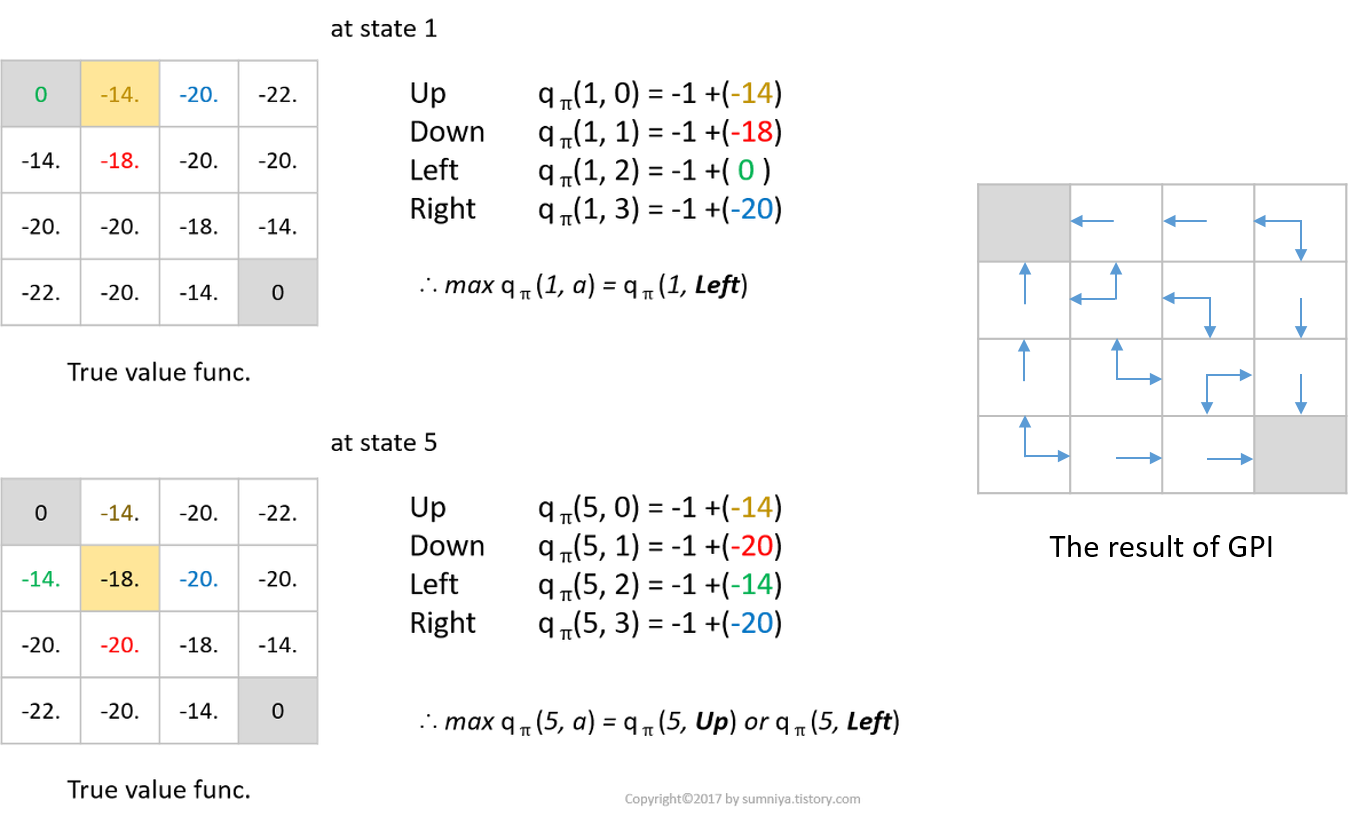
Value iteration
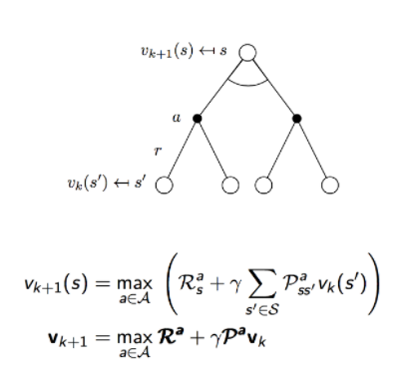
- Value Iteration은 Bellman Optimality Eqn.을 이용
- max값을 취해서 greedy하게 value func.을 구해 improve하는 아이디어
- action을 취할 확률을 곱해서 sum하는 대신에 max값을 취하는 optimal value func.식을 사용
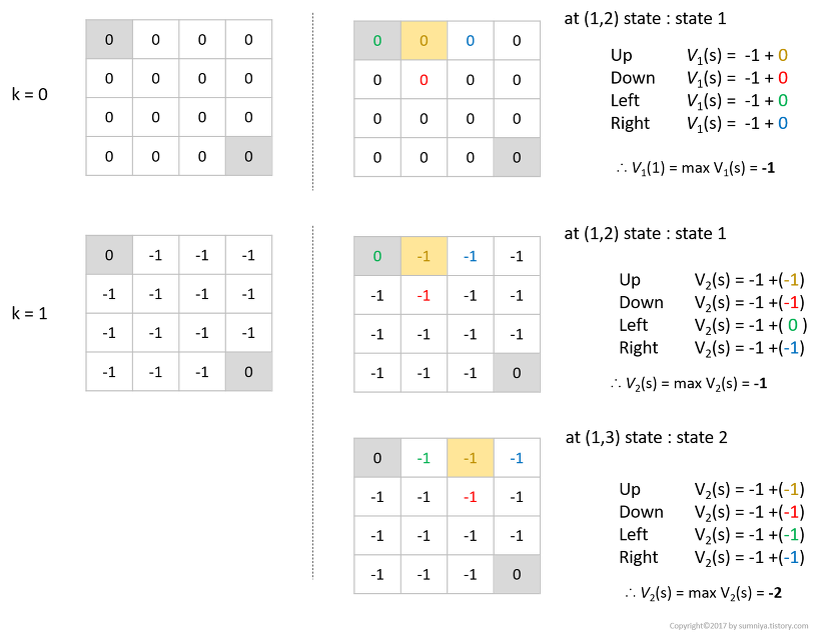
Example: Value Iteration
Leave a comment