You Only Look Once : Unified, Real-Time Object Detection 논문 리뷰
You Only Look Once Unified, Real-Time Object Detection 논문을 리뷰
YOLO
이미지 내의 bounding box와 class probability를 single regression problem으로 간주하여, 이미지를 한 번 보는 것으로 object의 종류와 위치를 추측한다. 아래와 같이 single convolutional network를 통해 multiple bounding box에 대한 class probablility를 계산하는 방식이다.

장점
- 간단한 처리과정으로 속도가 매우 빠르다. 또한 기존의 다른 real-time detection system들과 비교할 때,2배 정도 높은 mAP를 보인다.
- Image 전체를 한 번에 바라보는 방식으로 class에 대한 맥락적 이해도가 높다. 이로인해 낮은 backgound error(False-Positive)를 보인다.
- Object에 대한 좀 더 일반화된 특징을 학습한다. 가령 natural image로 학습하고 이를 artwork에 테스트 했을때, 다른 Detection System들에 비해 훨씬 높은 성능을 보여준다.
단점
- 상대적으로 낮은 정확도 (특히, 작은 object에 대해)
Unified Detection

-
Input image를 S X S grid로 나눈다.
-
각각의 grid cell은 B개의 bounding box와 각 bounding box에 대한 confidence score를 갖는다. (만약 cell에 object가 존재하지 않는다면 confidence score는 0이 된다.)
Confidence Score
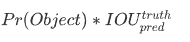
-
각각의 grid cell은 C개의 conditional class probability를 갖는다.
Conditional Class Probability
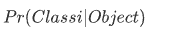
-
각각의 bounding box는 x, y, w, h, confidence로 구성된다.
(x,y): Bounding box의 중심점을 의미하며, grid cell의 범위에 대한 상대값이 입력된다.
(w,h): 전체 이미지의 width, height에 대한 상대값이 입력된다.
- 예1: 만약 x가 grid cell의 가장 왼쪽에 있다면 x=0, y가 grid cell의 중간에 있다면 y=0.5
- *예2: bbox의 width가 이미지 width의 절반이라면 w=0.5

Network Design
YOLO의 network architecture는 GoogLeNet for image classification 모델을 기반으로 한다. (24 Convolutional layers & 2 Fully Connected layers - 참고로 Fast YOLO는 위 디자인의 24의 convolutional layer를 9개의 convolutional layer로 대체한다.)
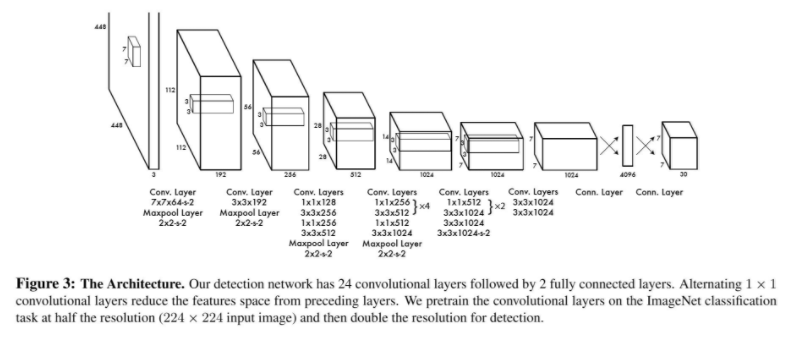
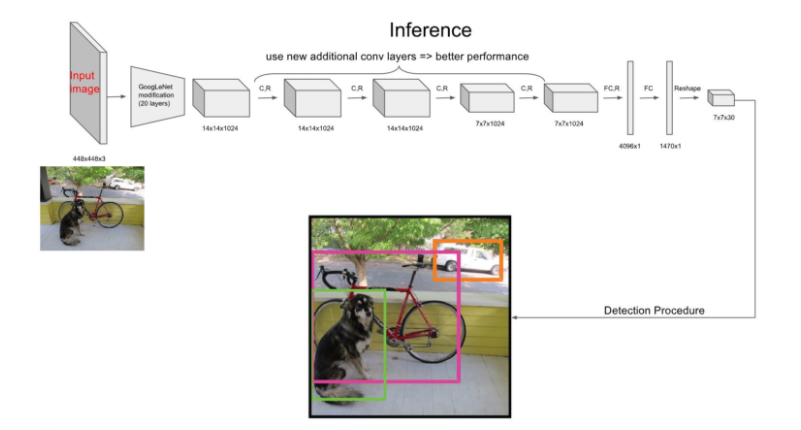
Inference Process
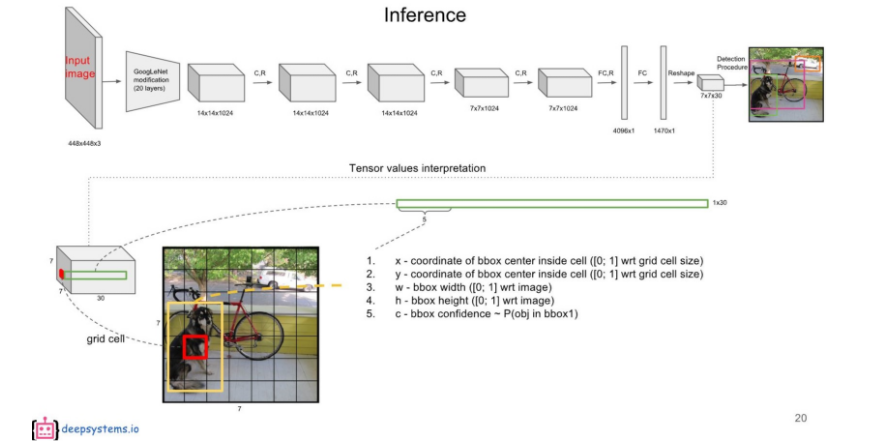
7X7은 49개의 Grid Cell을 의미한다. 그리고 각각의 Grid cell은 B개의 bounding Box를 가지고 있는데(여기선 B=2), 앞 5개의 값은 해당 Grid cell의 첫 번째 bounding box에 대한 값이 채워져있다.
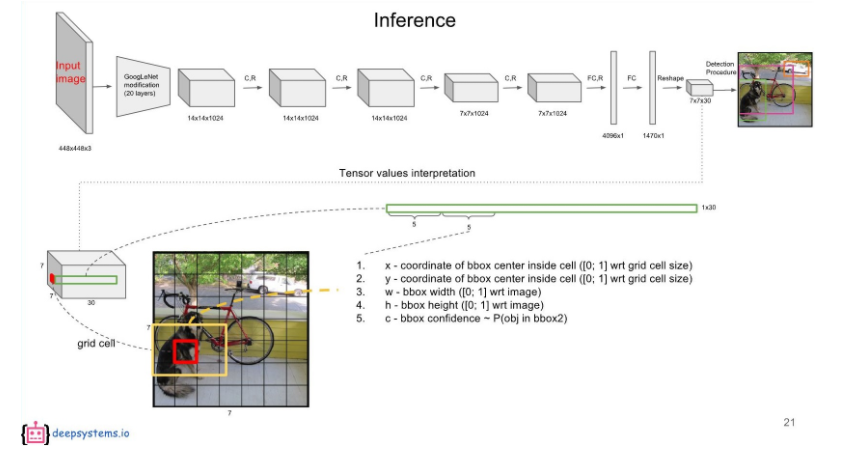
6~10번째 값은 두 번째 bounding box에 대한 내용이다.
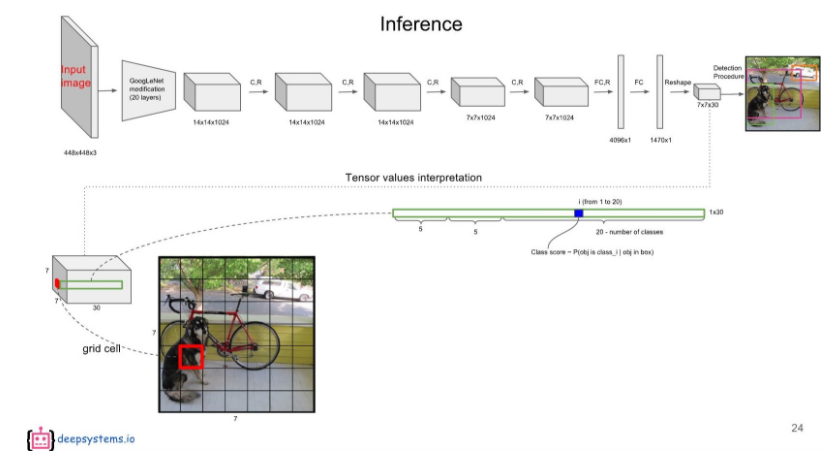
나머지 20개의 값은 20개의 class에 대한 conditional class probability에 해당한다.
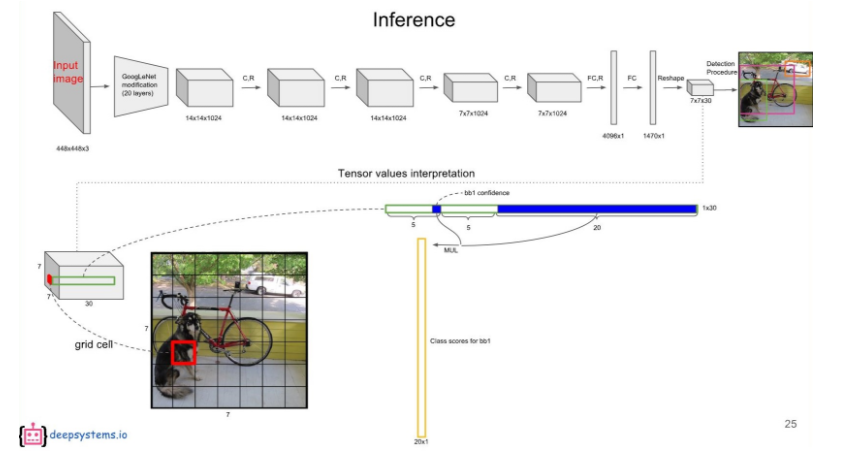
첫 번째 bounding box의 confidence score와 각 conditional class probability를 곱하면 첫 번째 bounding box의 class specific confidence score가 나온다. 마찬가지로, 두 번째 bounding box의 confidence score와 각 conditional class probability를 곱하면 두 번째 bounding box의 class specific confidence score가 나온다.
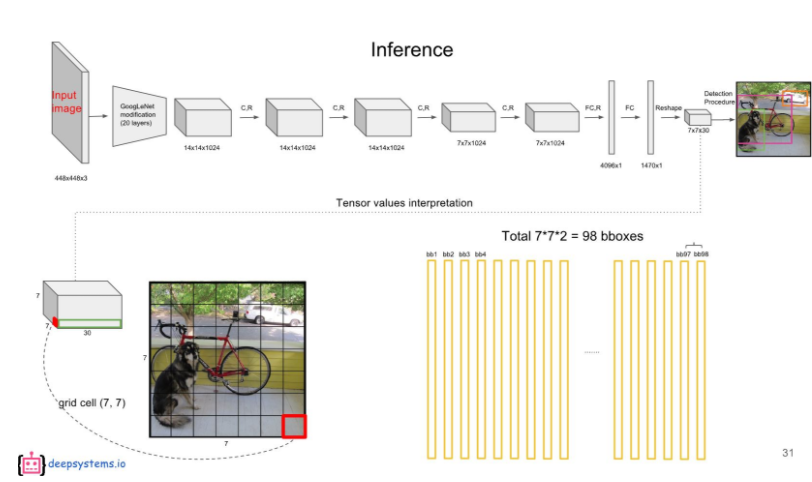
이 계산을 각 bounding box에 대해 하게되면 총 98개의 class specific confidence score를 얻을 수 있다.
이 98개의 class specific confidence score에 대해 각 20개의 클래스를 기준으로 non-maximum suppression을 하여, Object에 대한 Class 및 bounding box Location를 결정한다.
Training Process
YOLO의 Loss function을 이해하는 것으로 Training process에 대한 설명을 대신할 수 있을 것 같다. Loss function을 뜯어보기 전에 전제조건 몇 가지를 먼저 보도록 하자.
- Grid cell의 여러 bounding box들 중, ground-truth box와의 IOU가 가장높은 bounding box를 predictor로 설정한다.
- 1의 기준에 따라 아래 기호들이 사용된다.
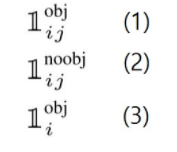
(1) Object가 존재하는 grid cell i의 predictor bounding box j (2) Object가 존재하지 않는 grid cell i의 bounding box j (3) Object가 존재하는 grid cell i 덧: Ground-truth box의 중심점이 어떤 grid cell 내부에 위치하면, 그 grid cell에는 Object가 존재한다고 여긴다.
Loss Function:
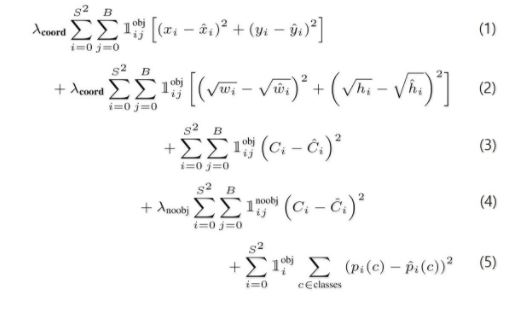
-
Object가 존재하는 grid cell i의 predictor bounding box j에 대해, x와 y의 loss를 계산.
-
Object가 존재하는 grid cell i의 predictor bounding box j에 대해, w와 h의 loss를 계산. 큰 box에 대해서는 small deviation을 반영하기 위해 제곱근을 취한 후, sum-squared error를 한다.(같은 error라도 larger box의 경우 상대적으로 IOU에 영향을 적게 준다.)
-
Object가 존재하는 grid cell i의 predictor bounding box j에 대해, confidence score의 loss를 계산. (CiCi=
-
Object가 존재하지 않는 grid cell i의 bounding box j에 대해, confidence score의 loss를 계산. (CiCi = 0)
-
Object가 존재하는 grid cell i에 대해, conditional class probability의 loss 계산. (Correct class c: pi(c)pi(c)=1, otherwise: pi(c)pi(c)=0)
λcoord: coordinates(x,y,w,h)에 대한 loss와 다른 loss들과의 균형을 위한 balancing parameter. λnoobj: obj가 있는 box와 없는 box간에 균형을 위한 balancing parameter. (일반적으로 image내에는 obj가 있는 cell보다는 obj가 없는 cell이 훨씬 많으므로)
Training YOLO
-
ImageNet 1000-class dataset으로 20개의 convolutioanl layer를 pre-training
-
Pre-training 이후 4 convolutioanl layers와 2 fully connected layers를 추가
-
Bounding Box의 width와 height는 이미지의 width와 height로 nomalize (Range: 0~1)
-
Bounding Box의 x와 y는 특정 grid cell 위치의 offset값을 사용한다 (Range: 0~1)
-
λcoord: 5, λnoobj: 0.5
-
Batch size: 64
-
Momentum: 0.9 and a decay of 0.0005
-
Learning Rate: 0.001에서 0.01로 epoch마다 천천히 상승시킴. 이후 75 epoch동안 0.01, 30 epoch동안 0.001, 마지막 30 epoch동안 0.0001
-
Dropout Rate: 0.5
-
Data augmentation: random scailing and translations of up to 20% of the original image size
-
Activation function: leaky rectified linear activation

Limitation of YOLO
- 각각의 grid cell이 하나의 클래스만을 예측할 수 있으므로, 작은 object 여러개가 다닥다닥 붙으면 제대로 예측하지 못한다.
- bounding box의 형태가 training data를 통해서만 학습되므로, 새로운/독특한 형태의 bouding box의 경우 정확히 예측하지 못한다.
- 몇 단계의 layer를 거쳐서 나온 feature map을 대상으로 bouding box를 예측하므로 localization이 다소 부정확해지는 경우가 있다.
Experiments
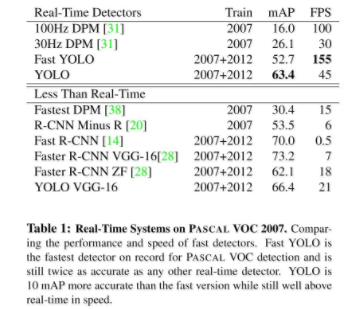
Table1: 다른 real-time object detect system들에 비해 높은 mAP를 보여준다. Fast YOLO의 경우 가장 빠른 속도를 보여준다.
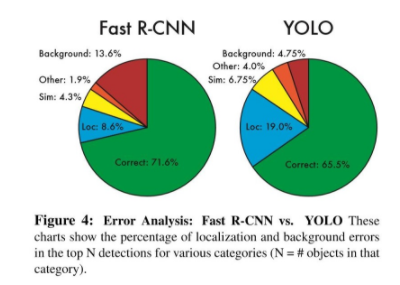
Figure4: Fast R-CNN과 비교했을 떄, 훨씬 적은 False-Positive를 보여준다. (low backgound error)
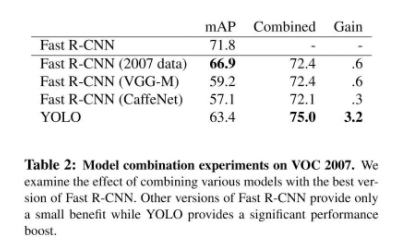
Table2: Fast R-CNN과 같이 동작하면 Fast R-CNN을 보완하는 역할을 할 수 있다. (low backgound error)
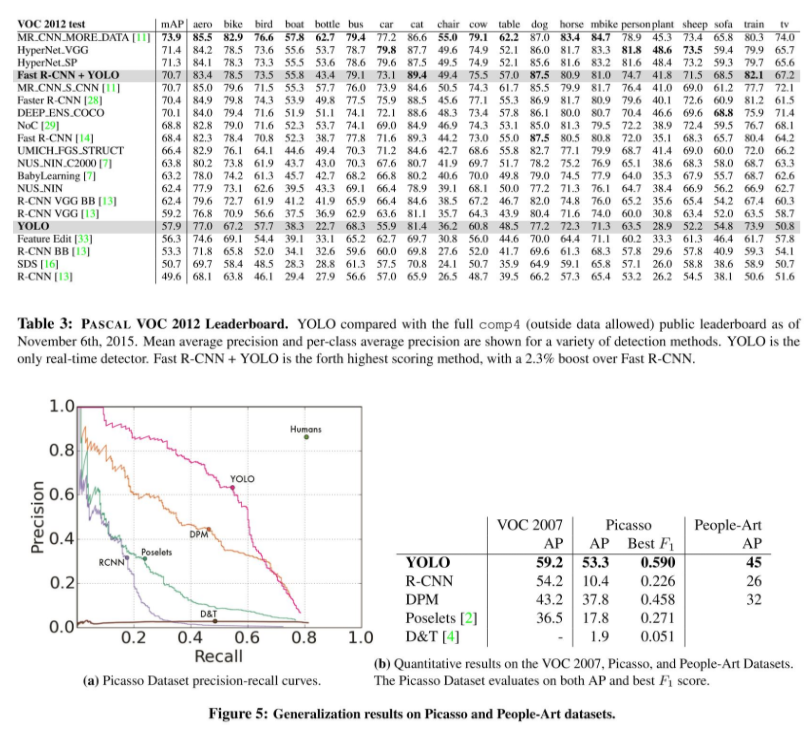
Figure5: Natural image training -> Artwork detection 에서 매우 강한 면모를 보인다.
Conclusion

Leave a comment