Deeplab 논문 리뷰
Semantic Segmentation에서 좋은 성능을 갖는 Deeplab논문을 리뷰
Segmentation

object detection (Faster rcnn) : Object Detection은 각각의 객체를 분류가능하지만 Segmentation은 안됨
Semantic Segmentation (FCN) :Sementic Segmentaion은 Segmention는 가능하지만 각각분류 불가능
Instance Segmentation (FCN on BBOX) : 두개를 더해서 Segmentation과 분류가능
Fully Convolutional Networks
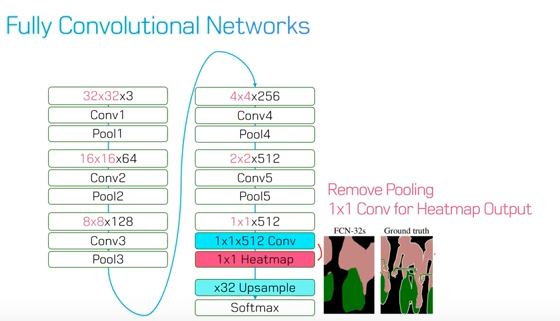
- Feature Extraction : 일반적인 CNN의 구조에서 많이 보이는 conv layer들로 구성되어있음
- Feature-level Classification : 추출된 Feature map의 pixel 하나하나마다 classification을 수행합니다. 이 때 classification된 결과는 매우 coarse함
- Upsampling : coarse 한 결과를 backward strided convolution 을 통해 upsampling하여 원래의 image size로 키워줌
- Segmentation : class별 heatmap을 softmax를 이용하여 가장 높은 확률을 가지는 class만 모아서 한장의segmentation 이미지로 만듬

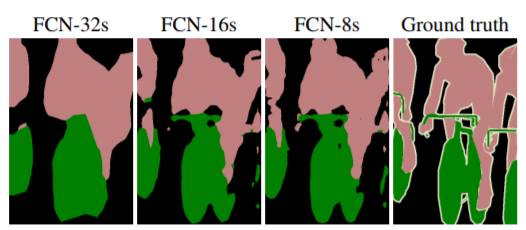
최종 결과물인 FCN-32s는 32배로 upsampling을 하기 때문에 detail이 많이 사라진 segmentation 결과를 보여줌
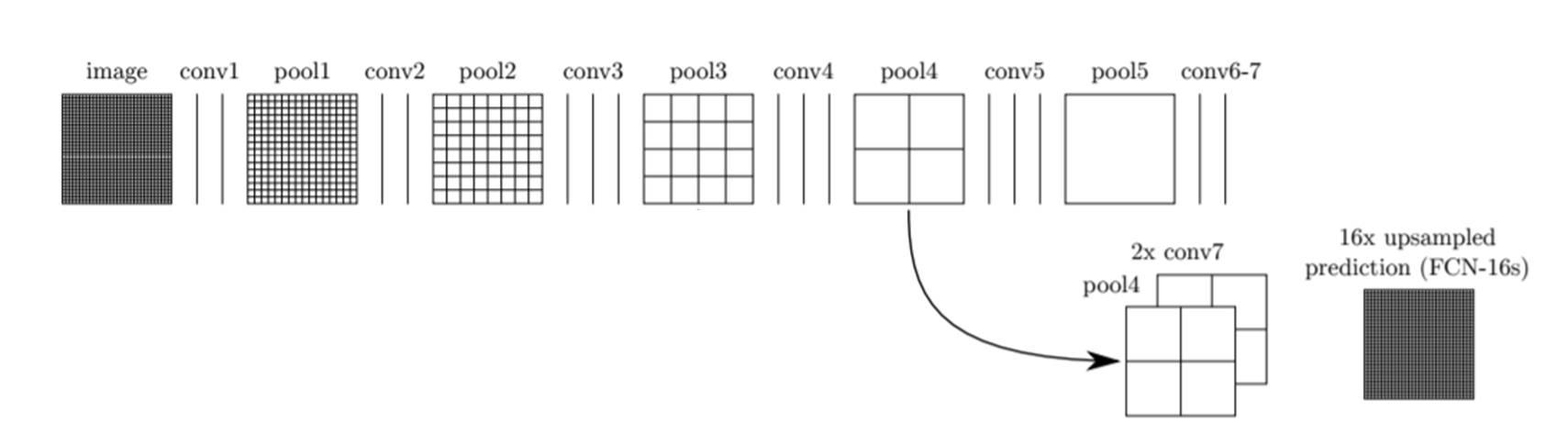
이 문제를 해결하기 위해 그 이전 layer의 feature map을 이용하는 skip combining 기법을 사용
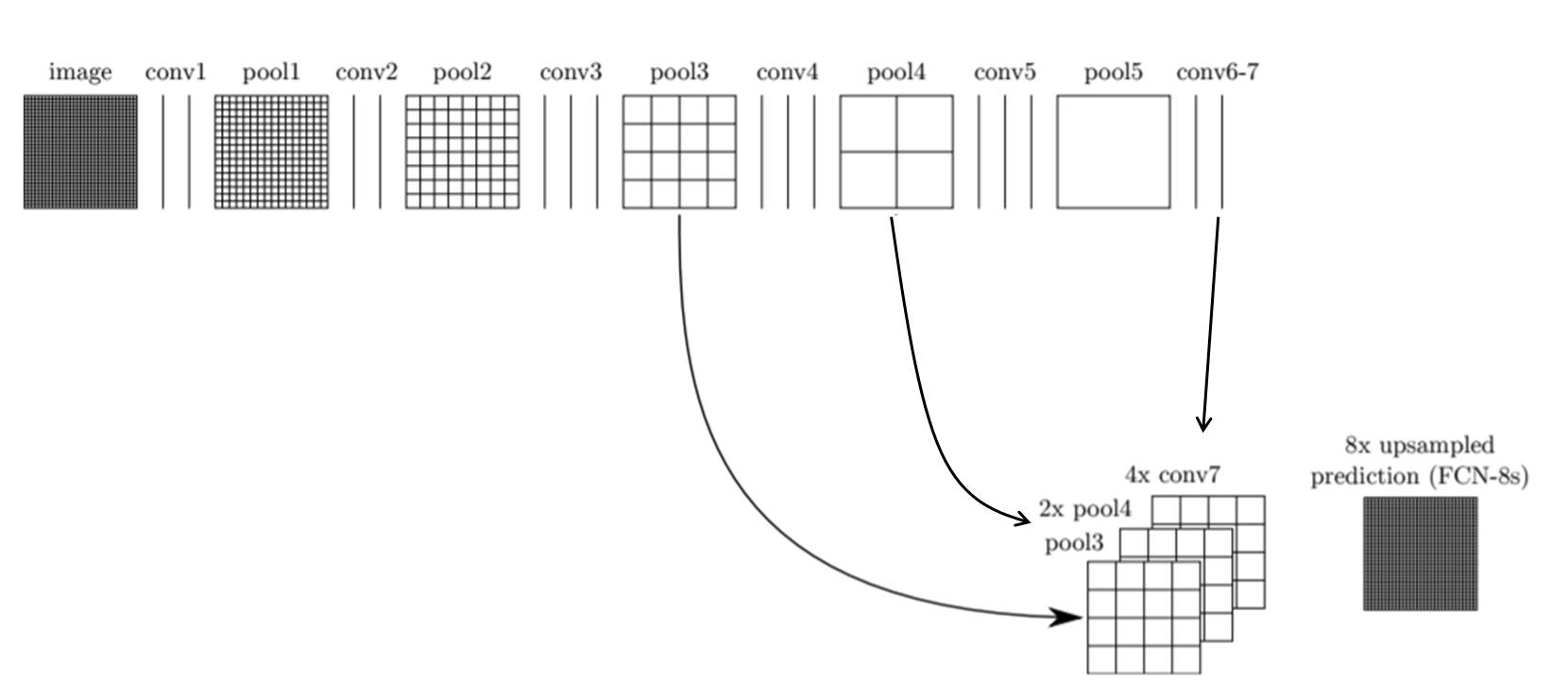
Pooling을 하는 이유 : Global Feature를 multi-scale로 보기위해(classification관점)
Semantic segmentation은 픽셀 단위의 조밀한 예측이 필요한데 pooling을 사용하면 feature-map의 크기가 줄어들기 때문에 detail한 정보를 얻는데 어려움
Dense Prediction을 위해서
-
Up-convolutions -> Downsample(pooling)할 필요가 있는가?
-
Multi-scale Inputs -> Scale의 Input을 별개로 처리할 필요가 있는가?
DeepLab
- DeepLab V1 Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. ICLR 2015.
- DeepLab V2 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. TPAMI 2017.
- DeepLab V3 Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017.
- DeepLab V3+ Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018.
V1에서는 atrous convolution을 적용
V2에서는 multi-scale context를 적용하기 위한 Atrous Spatial Pyramid Pooling (ASPP) 기법을 제안
V3에서는 기존 ResNet 구조에 atrous convolution을 활용해 좀 더 dense한 feature map을 얻는 방법을 제안
V3+에서는 separable convolution과 atrous convolution을 결합한 atrous separable convolution의 활용을 제안
DeepLab V1
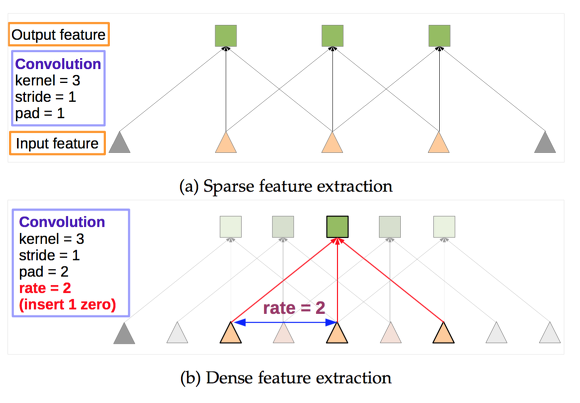
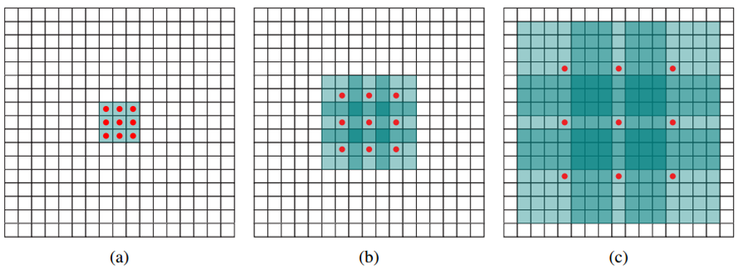
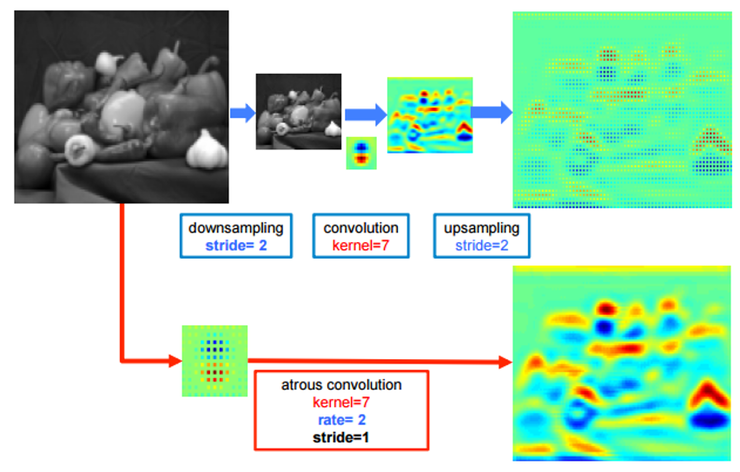
Dilated Convolution / Atrous Convolution
보통 semantic segmentation에서 높은 성능을 내기 위해서는 convolutional neural network의 마지막에 존재하는 한 픽셀이 입력값에서 어느 크기의 영역을 커버할 수 있는지를 결정하는 receptive field 크기가 중요하게 작용
pooling의 효과를 -> dilated convolution으로 parameter수를 유지하며 resolution이 줄어드는 것을 막는다.
기존 convolution과 동일한 양의 파라미터와 계산량을 유지하면서도, field of view (한 픽셀이 볼 수 있는 영역) 를 크게 가져갈 수 있음
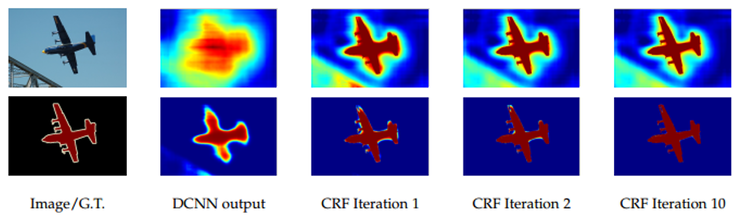
CRF : Conditional Random Fields
후처리 과정으로 사용하여 픽셀 단위 예측의 정확도를 높일수있음
DeepLab v2
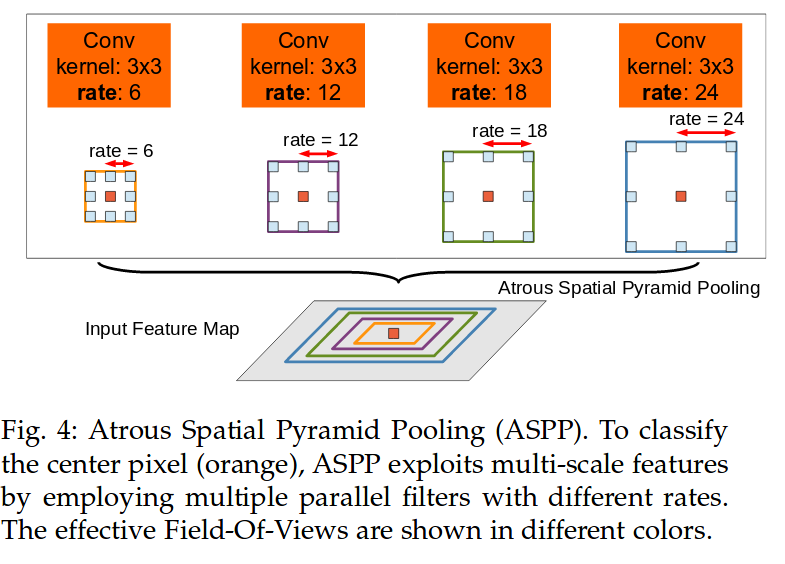
Atrous Spatial Pyramid Pooling
- Dilated Conv만으로는 Multi-scale을 본다고 하기 어렵다
- Dilated Conv는 Pooling 대신 Resolution 유지를 위해 사용하는 것
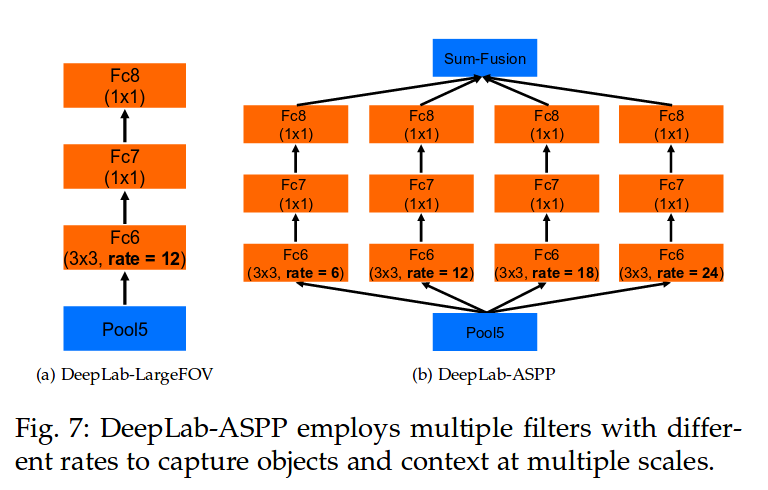
DeepLab v3
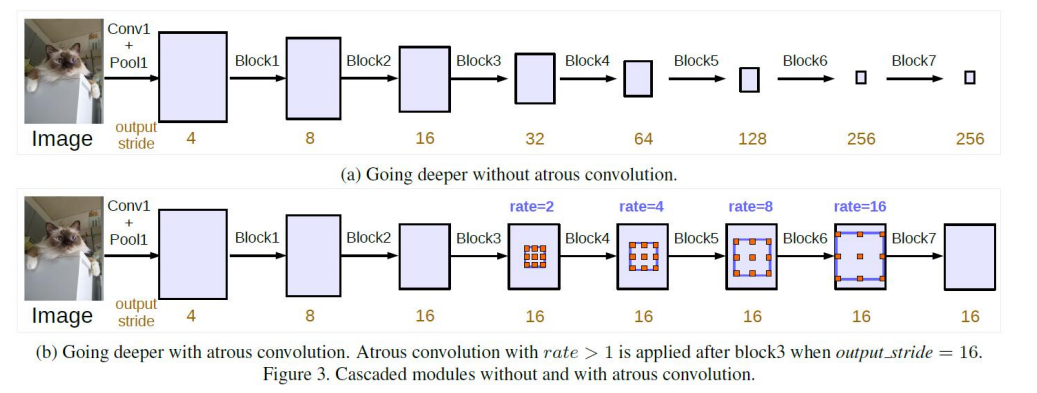
Cascaded modul
when output stride = 16 and Multi Grid = (1, 2, 4), the three convolutions will have rates = 2 · (1, 2, 4) = (2, 4, 8) in the block4, respectively.
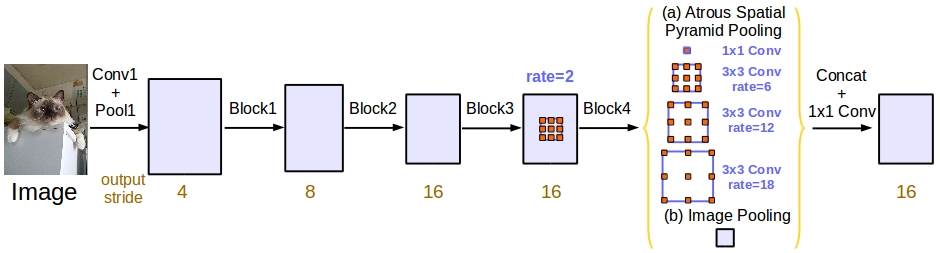
Modified ASSP + Batch Normalization
1x1 conv + GAP
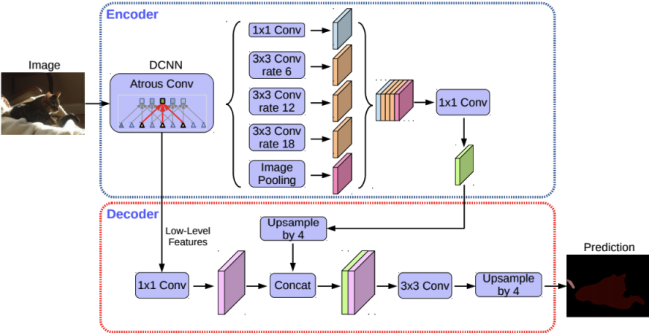
DeepLab v3+
Encoder-Decoder
Result
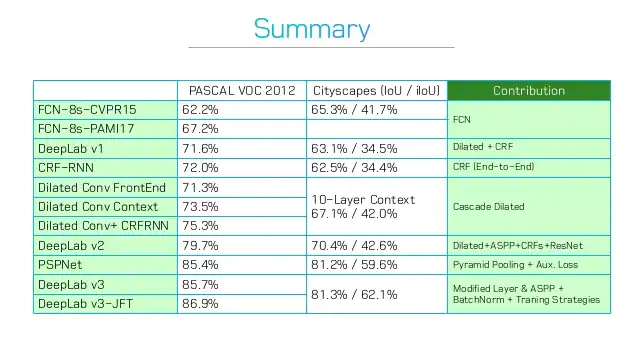
DeepLabv3+ (Xception) 87.8
DeepLabv3+ (Xception-JFT) 89.0
Leave a comment