Docker환경에서 TensorRT를 활용한 Object Detection모델 최적화 및 Inference방법
TensorRT 컨테이너 생성하여 학습모델을 UFF변환하고 Inference하는 예제를 정리
공식 가이드 문서 https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html 을 참고하여 작성
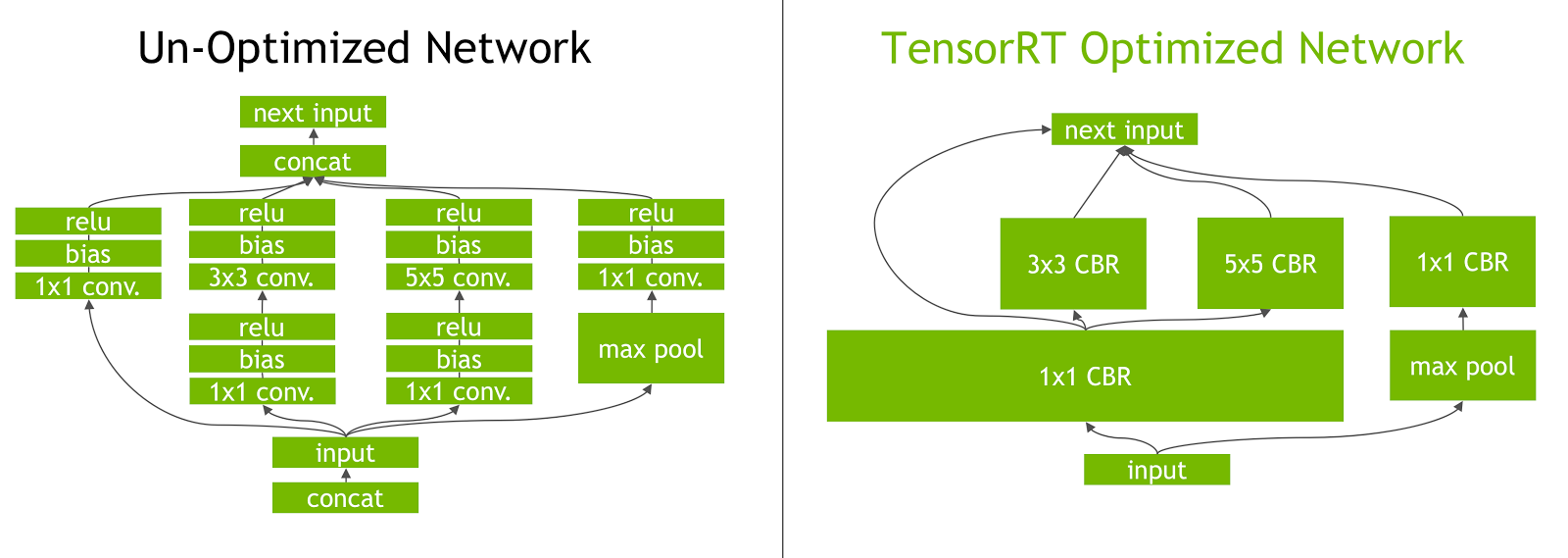
TensorRT의 최적화 방법
- Convolution + Bias + Activation 연산을 한번에 처리하도록 최적화
- Tensorflow Graph > UFF > TensorRT Engine > Inference
TensorRT 컨테이너 생성
-
docker 이미지 받기
docker pull nvcr.io/nvidia/tensorrt:19.09-py3 -
nvidia-docker로 이미지 컨테이너 생성
nvidia-docker run -it --name tensorrt nvcr.io/nvidia/tensorrt:19.09-py3
Sample 예제
C++ mnist 예제
-
sample코드 make로 빌드
cd /workspace/tensorrt/samples make -j4 -
빌드가 완료되면 /workspace/tensorrt/bin에 실행파일이 생성됨
./sample_mnist ./sample_uff_mnist ./sample_onnx_mnist
python classification 예제
-
TensorRT컨테이너에 TensorFlow, Pytorch가 포함되있지 않기 때문에 python 패키지 및 convert-to-uff 변환 유틸리티 설치가 필요함
/opt/tensorrt/python/python_setup.sh -
python sample코드 실행
python caffe_resnet50.py -d /workspace/tensorrt/python/data python uff_resnet50.py -d /workspace/tensorrt/python/data python onnx_resnet50.py -d /workspace/tensorrt/python/data -
/workspace/tensorrt/python/data 폴더에 있는 이미지중 랜덤하게 inference하여 결과를 보여줌
Correctly recognized /workspace/tensorrt/python/data/resnet50/tabby_tiger_cat.jpg as tabby
Object detecion(SSD)모델 예제
-
/workspace/tensorrt/samples/python/uff_ssd 경로에 requirements 패키지 설치
pip install -r requirements.txt -
FlattenConcat custom plugin layers 사용을 위한 빌드
mkdir -p build cd build cmake .. make cd .. -
uff 변환 및 inference
python detect_objects.py <IMAGE_PATH>- 예제소스에서는 ssd_inception_v2_coco_2017_11_17 model을 다운로드하여 uff파일로 변환한 후에 inference함
- 또는 convert-to-uff 명령어로 pb파일을 uff로 변환 가능함
convert-to-uff --input-file frozen_inference_graph.pb -O NMS -p /workspace/tensorrt/samples/sampleUffSSD/config.py–input-file : path to input model
-o : name of output uff file
-O : output nodes of the model
-p: preprocessing file to run before handing the graph
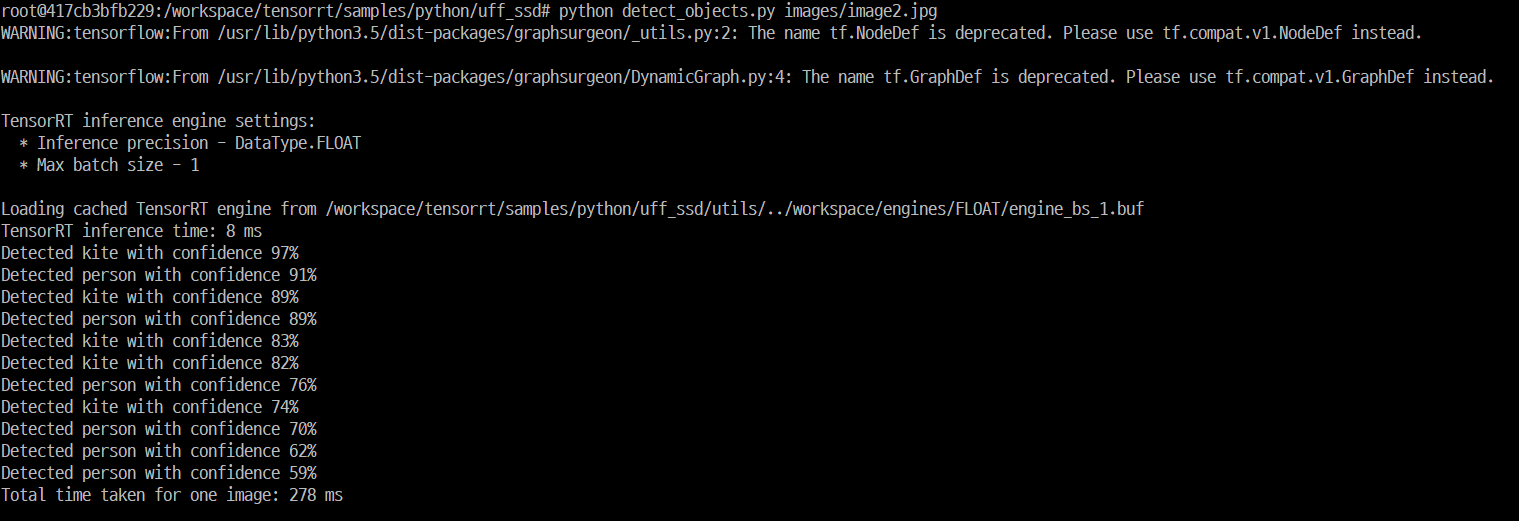
- 결과확인(SSD모델에서 inferece time은 8 ms, 총 소요시간은 278ms)

Leave a comment